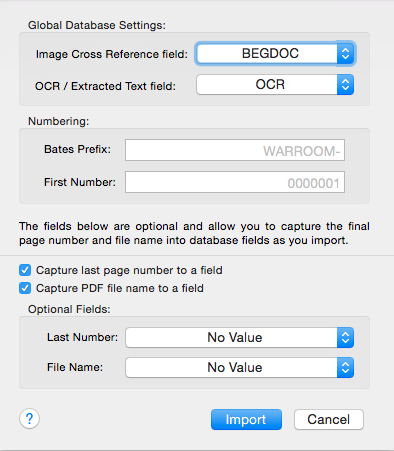
To import PDF files directly into your project, go to the "Images" menu in the menu bar and select "Import PDFs".
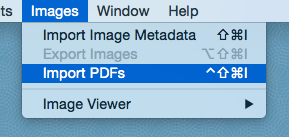
This will bring up the Import PDF dialog box. On this screen you must first choose an Image Cross Reference field and a OCR / Extracted Text field to hold the beginning bates number and the full text of your PDFs, respectively. If you have not created these fields yet, cancel out of the Import PDF dialog box and click the gear button to enter the Modify Fields screen (see the Help section for “Modifying Fields” for more information on creating and modifying database fields). Alternatively, you can create a new PDF database pre-populated with the requisite fields, directly from the WarRoom Projects Window (Window > Projects Window from the menu).
You have the option of entering a bates number prefix for your documents on the Import PDFs screen, as well as entering a starting page number. Finally, if you have an "ending bates" or "last page number" field in your database, you can capture the last page number of each document as you import it in the bottom section of the screen. You also have the option of capturing the PDF file name to a text field at the bottom. Once you are ready to import your PDFs, click the "Import" button and select the files. Please note that WarRoom does not provide an OCR function, so your PDF files must already be full text searchable before WarRoom can extract the full text to add to the database.