Importing OCR:Occasionally, as part of an electronic document production, you may receive the full text for each document record in a separate folder (often named “Extracted Text”, “TEXT”, or “OCR,” which is an abbreviation for “Optical Character Recognition”). This folder will contain numerous text files, one for each document included in the metadata load file. While this information can be included in the metadata load file, sometimes it is preferable to receive it separately so that you can choose whether or not to load it.
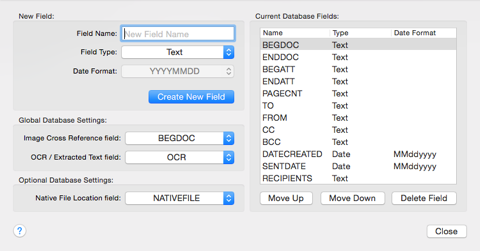
To load these OCR / extracted text files to your database, you must first go to File > Database Administration > Modify Fields in the menu and make sure that you have created a text field to hold the OCR / extracted text (see the Help section for “Modifying Fields” for more information on creating and modifying database fields). Also make sure that you select this field in the global “OCR / Extracted Text” drop down window:
Next, open the Import OCR / Extracted Text window by going to Documents > Import OCR / Extracted Text in the menu.
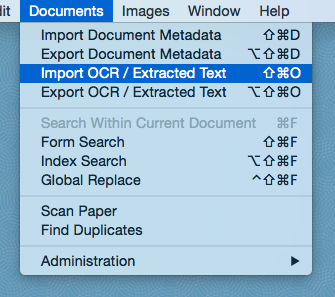
Select the Image Cross Reference field and OCR / Extracted Text field if they are not already selected, and click Import. Browse to the folder containing your OCR / extracted text files and select all of the ones that you want to import. If you want to import all of them, you can select all of the files within the folder by hitting Command-A or by holding down Shift on the keyboard while clicking the first and last file. Once you are ready, click OK and WarRoom will pull the text from these documents and insert it into the OCR / Extracted Text field in your database for the document whose image cross reference matches the file name.